
A data structure organizes related data in a computer so that it can be used efficiently.
Different kinds of data structures are suited to different kinds of applications, and some are highly specialized to specific tasks. For example, graphs are used to represent connections on social websites (such as Twitter, Facebook), trees are used to represent hierarchical data, such as files and folders in a filesystem, queues can be used to create task schedulers, compiler implementations usually use hash tables to look up identifiers, binary trees are used in searching algorithms, etc.
Usually, choosing the correct data structure is key to designing an efficient algorithm.
Some of the most common data structures are:
- Array
- Linked List
- Stack, Queue
- Graph, Tree
- Hash Table
Some data structures can be used to create others, for example, linked lists can be used to create stacks and queues.
"Each data structure has a set of operations that can be performed on the data it stores. We select a data structure based on the operations required to implement an algorithm."
Array
Array, is a data structure consisting of a collection of elements (values or variables), each identified by at least one array index or key. An array is stored so that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.For example, an array of 10 32-bit integer variables, with indices 0 through 9, may be stored as 10 words at memory addresses 2000, 2004, 2008, ... 2036, so that the element with index i has the address 2000 + 4 × i.
Linked List
The linked list data structure is often used to implement other data structures.A linked list is a sequence of nodes where each node stores its own data and a pointer (address) to the location of the next node.
One node links to another forming what can be thought of as a linked chain:
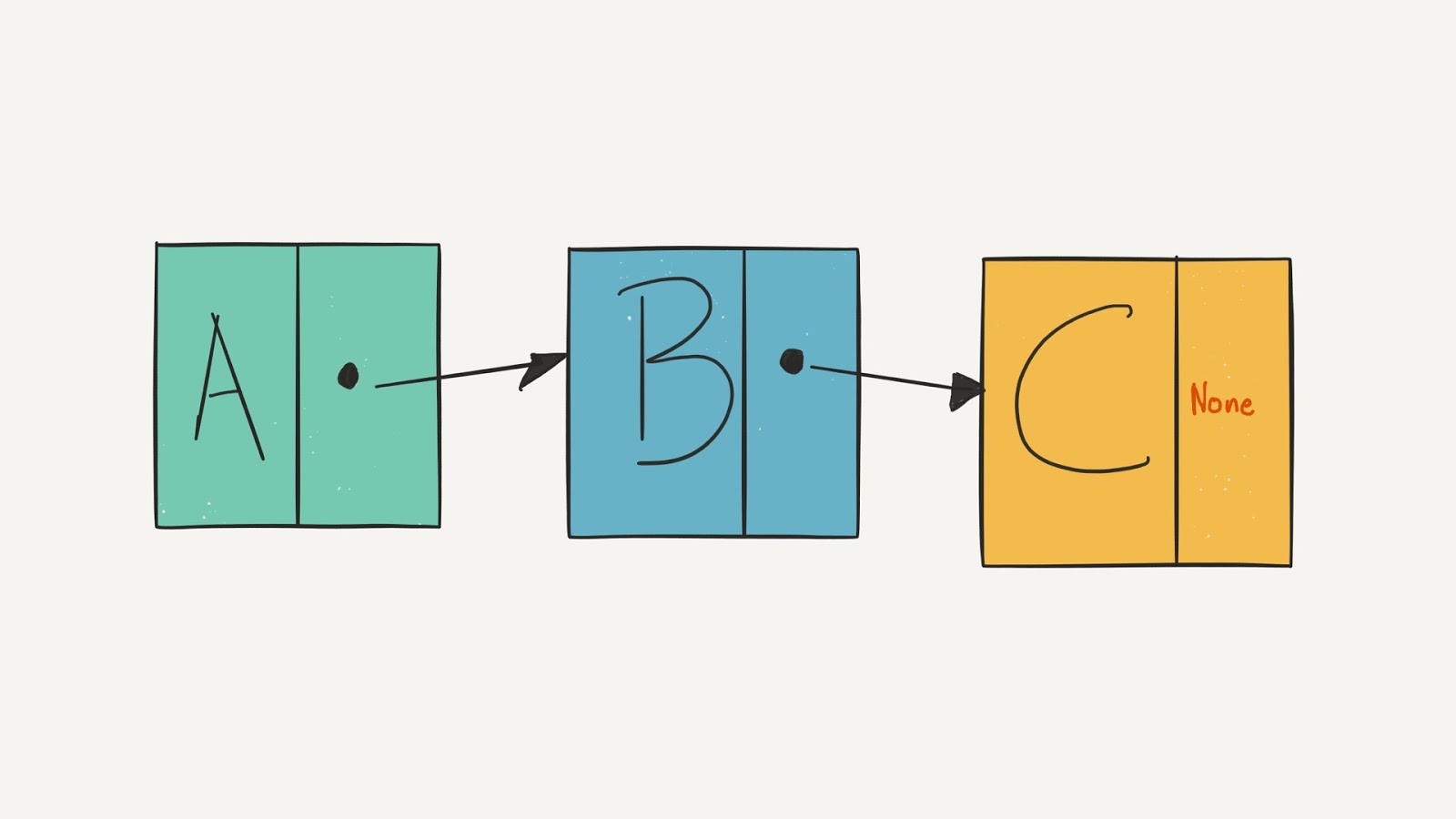
The last item in the list has a link to NULL, indicating the end of the chain.
Advantages:
Although a linked list is similar to an array, it is not restricted to a declared number of elements. Additionally, unlike an array which stores data contiguously in memory or on disk, a linked list can easily insert or remove elements without reallocation or reorganization of the entire structure because the data items need not be stored contiguously.
Linked List Drawbacks:
1) Random access is not allowed. We must access nodes sequentially starting from the first one. Therefore, we cannot do a binary search on a linked list.
2) Extra memory space for a link is required for each element of the list.
"Linked lists are generally used as the fundamental building block for implementing data structures such as stacks, queues, trees, and graphs."
Stack
A stack is a simple data structure that adds and removes elements in a particular order.Every time an element is added, it goes on the "top" of the stack. Only an element at the top of the stack can be removed, just like a stack of plates. This behavior is called LIFO (Last In, First Out).

Terminology
Adding a new element onto the stack is called push.
Removing an element from the stack is called pop.
Stacks can be used to create undo-redo functionalities, parsing expressions (infix to postfix/prefix conversion), and much more.
"A stack can be implemented using an array or a linked list."
Queue
A queue is a simple data structure that allows elements to be inserted from one end, called the rear (also called tail), and deleted from the other end, called the front (also called head).This behavior is called FIFO (First in First Out).

Terminology
The process of adding new elements into the queue is called enqueue.
The process of removal of an element from the queue is called dequeue.
Applications
Queues are used whenever we need to manage objects in order starting with the first one in.
Scenarios include printing documents on a printer, call center systems answering people on hold people, and so on.
"A queue can be implemented using an array or a linked list."
Graph
Graphs are used to represent many real-life applications like networks, transportation paths of a city, and social networks such as Facebook where each person represents a single node. Graphs are useful in many applications of computer science as well.A graph is a set of connected nodes where each node is called a Vertex and the connection between two of them is called an Edge. We define a Graph as a data structure that consists of finite vertices and edges.
There are two types of graphs, undirected (A) and directed (B):

Undirected Graphs
Image A is an example of an undirected graph. Here, the edges do not have directions, meaning that if the vertex u is connected to v, then v is connected to u.
Undirected graphs usually are drawn with straight lines between the vertices (no arrows).
Example: On Facebook, if user A is a friend of user B, that automatically means that user B is a friend of user A.
Directed Graphs
Image B is an example of a directed graph. Here, each edge has a defined direction, which is usually represented with arrows. Having u connected to v does not necessarily mean that v is connected to u.
Example: On Twitter, if user A follows user B, then user B does not necessarily follow user A back.
Two of the most commonly used implementations of graphs are:
1. Adjacency Matrix
2. Adjacency List
Check out the implementations below!
Binary Tree
Unlike linear data structures (Arrays, Linked Lists, Stacks, and Queues), Binary trees are hierarchical. They consist of interconnected nodes. The topmost node is called the root. For a given node, the nodes that are directly under are called its children.
The tree is called binary because each node can have at most two children.
The node directly above another node is called its parent.
The tree which is a child of a node is called subtree.
Elements with no children are called leaves.
The maximum number of nodes from root to leaf is called the height.
Check out the image below for a visual representation of these terms:

Types
There are various types of binary trees, each having characteristics suitable for its purpose.
Full Binary Tree
A binary tree is considered full if every node has 0 or 2 children.
Complete Binary Tree
A binary tree is considered complete if all levels are completely filled except possibly the last level and the last level has all nodes as far left as possible.
Perfect Binary Tree
A binary tree is considered perfect if all internal nodes have two children and all leaves are at the same level.
Advantages
- Trees reflect structural relationships in the data, and are used to represent hierarchies.
- Trees provide efficient insertion and searching.
- Trees are very flexible, allowing subtrees to be moved around with minimum effort.
"One of the most common applications of the binary tree is the Binary Search Tree (BST), which is used in many search applications."












{kind=link}